Image Mixing via Token Merge
Step 1: Image Policy with Token Merging
We utilize a ViT model $f_\theta(\cdot)$ where $N$ attention layers are replaced with ToMeAttention. For an initial sequence $Z_L$, tokens are merged via Bipartite Soft Matching (BSM) to reduce redundancy:
Here, $A_K$ represents the condensed attention map, and $S$ is the Source Matrix, which tracks the spatial relationship between the raw tokens ($Z_L$) and the merged tokens ($Z_K$).
Step 2: Generating Mixing Mask with Source Matrix
To avoid the information loss typical of greedy "Top-K" selection, we introduce a recovery function $\mathcal{R}_{K \to L}$. This mechanism expands the merged attention map back to the original resolution using the source matrix $S$:
This ensures that attention values are propagated over the original token topology, preserving contextual continuity and spatial dependencies. The final mixing mask $\mathcal{M}$ is generated by selecting the most significant regions from the recovered attention map $\hat{A}_L$:
where $p = \lfloor\lambda \times L \rfloor$ determines the mixing threshold. This mask is then used to combine image patches from the mini-batch to create augmented training data, $\hat{x}$ = $\mathcal{M} \odot x_i$ + $(1 - \mathcal{M}) \odot x_j$.
Step 3: Re-scaling Policy for Mixing Ratio
Standard mixup methods often rely on simple spatial ratios. In contrast, MergeMix introduces an adaptive policy that considers the degree of information integration within the model, utilizing both merged tokens and mask density. The refined mixing ratio $\hat{\lambda}$ is sampled from a Gaussian distribution and normalized:
where $\mu = \frac{K}{L}$ is the mean of the Gaussian distribution and $\sigma = \frac{p}{\sum \mathcal{M}}$ is the standard deviation.
This Gaussian-based sampling ensures a smooth transition between samples, alleviating the abruptness of linear mapping and resulting in more robust data augmentations.
Step 4: Loss Function of Image Classification
The model is optimized using a composite loss function $\mathcal{L}_{\text{Total}}$, which balances the mixed data supervision with standard one-hot classification:
where $\hat{x}$ is the mixed input, $y_i$ and $y_j$ are the source labels, $y$ is the target label, and $\hat{\lambda}$ is the dynamic mixing ratio.
Results of Image Classification
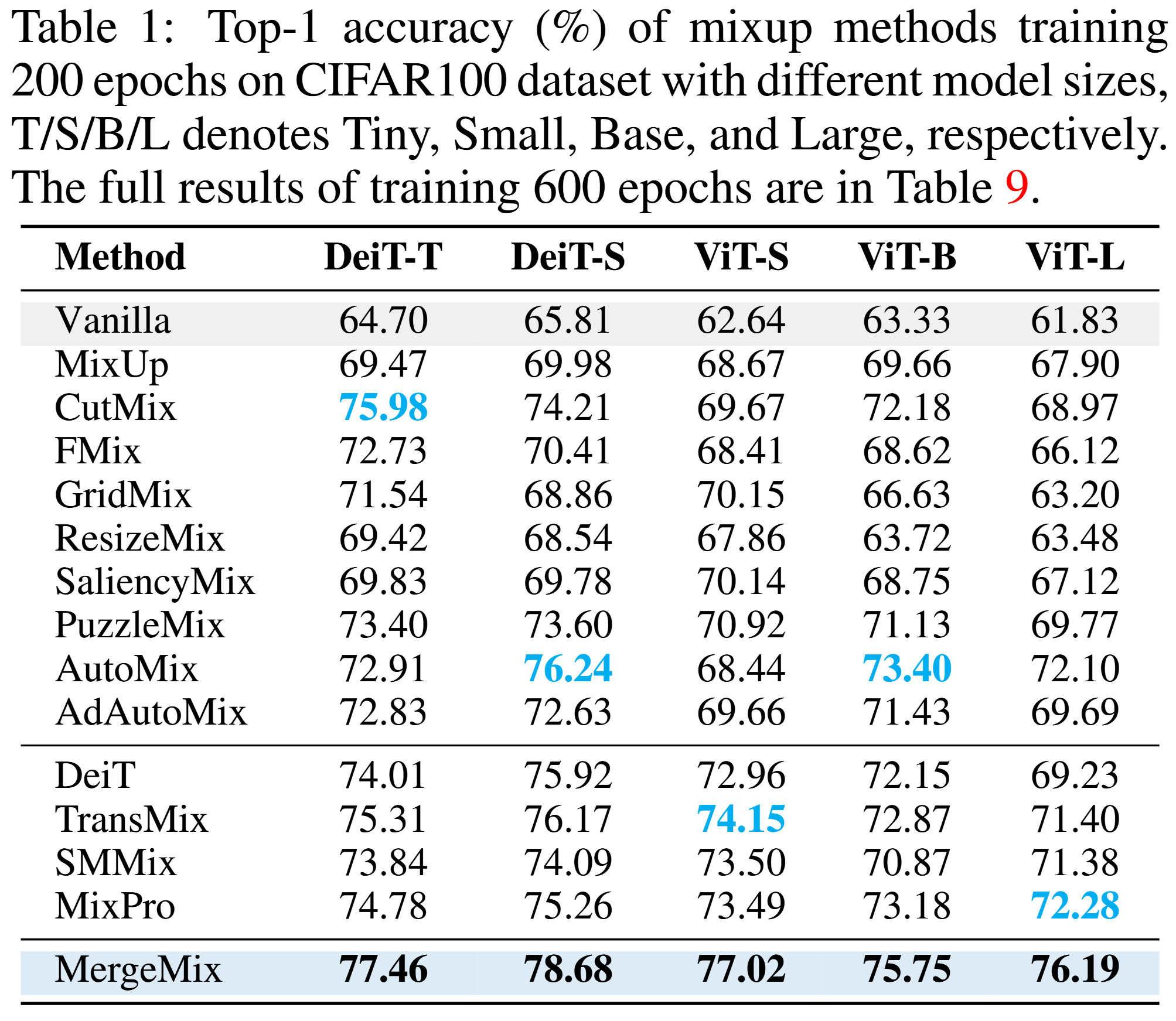
CIFAR100 dataset classification (part)
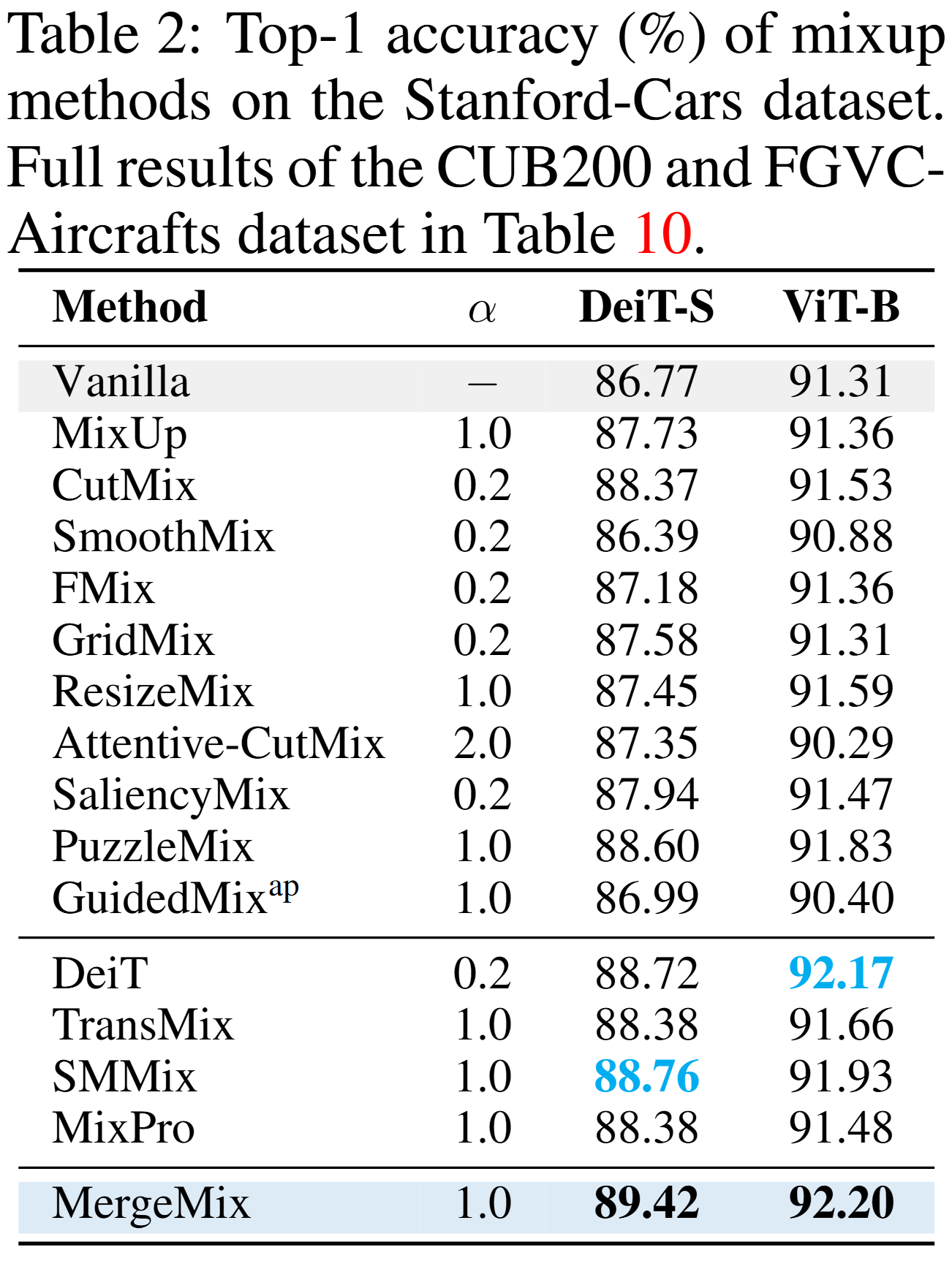
Stanford-Cars dataset classification
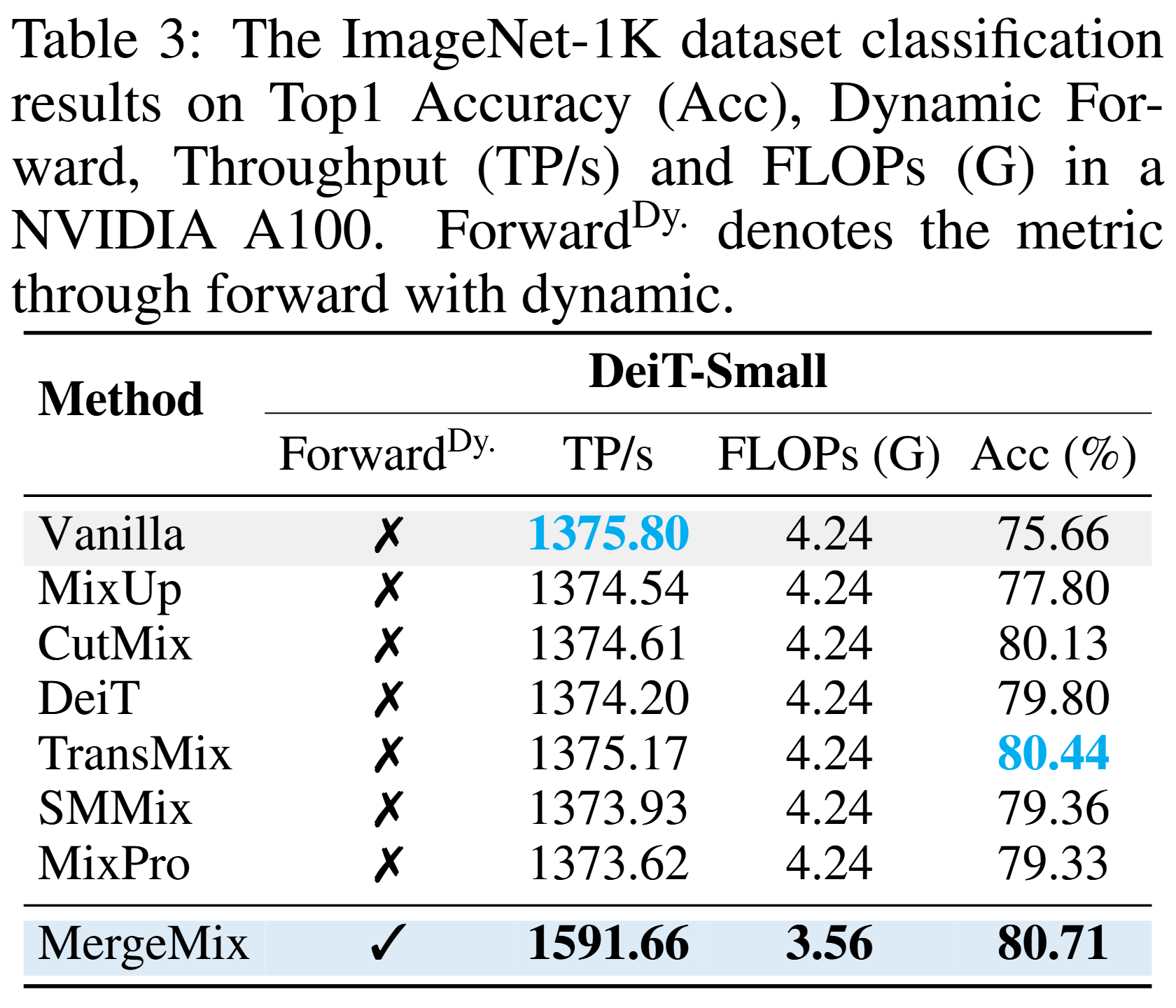
ImageNet-1K dataset classification
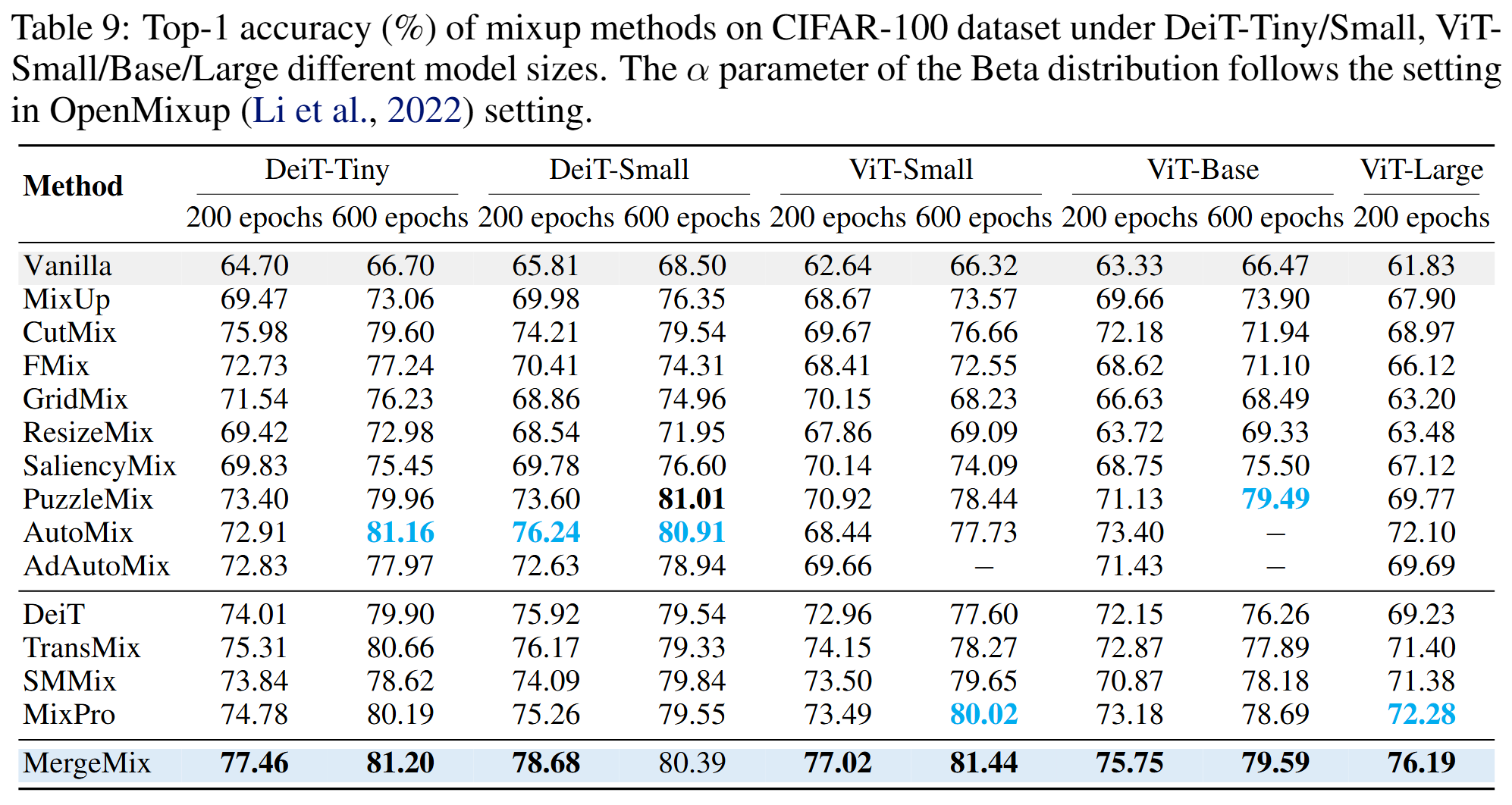
CIFAR100 dataset classification (full)
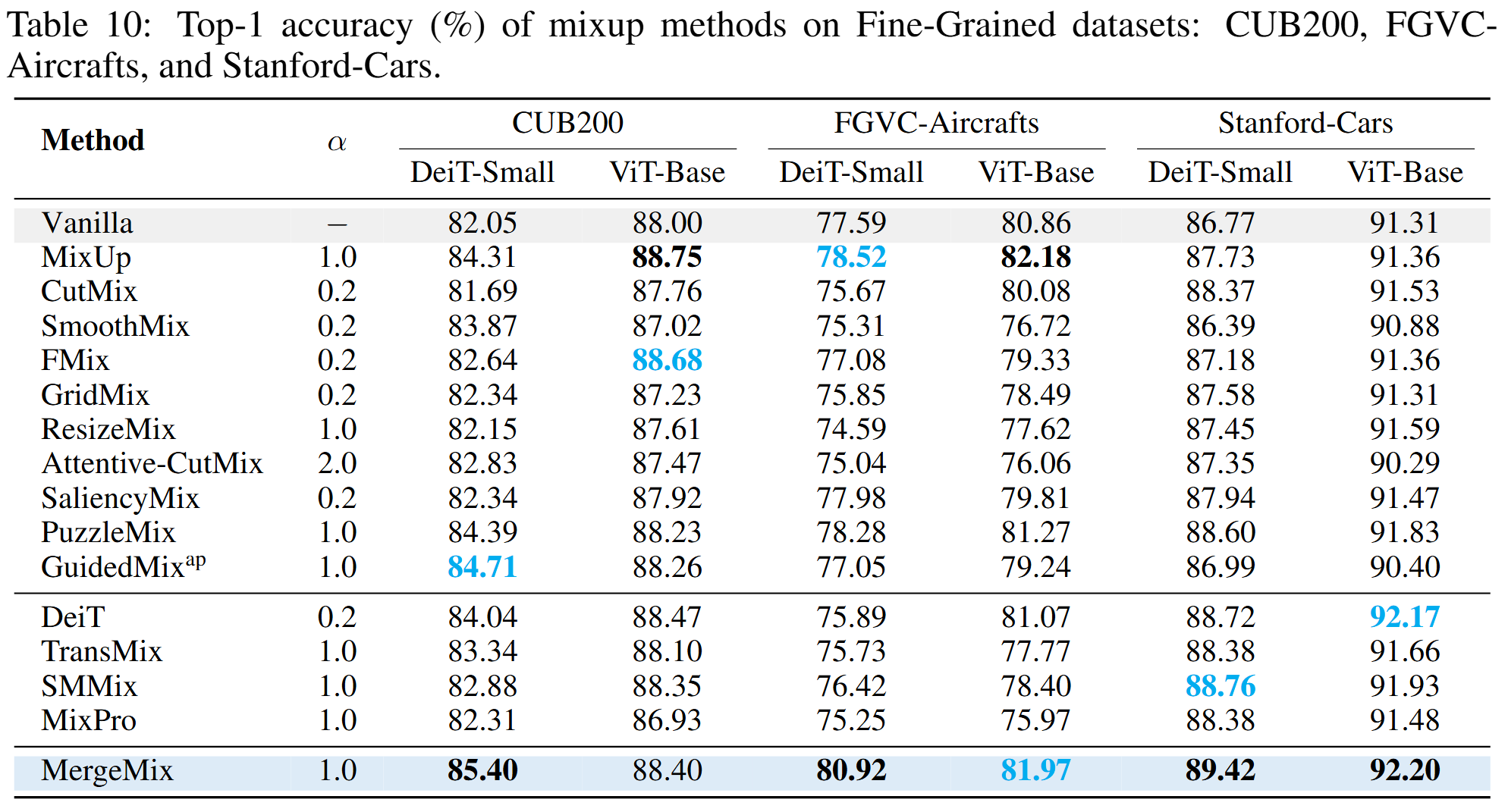
CUB200, FGVC-Aircrafts, and Stanford-Cars datasetes classification

MetaFormer Results
Results of Calibration
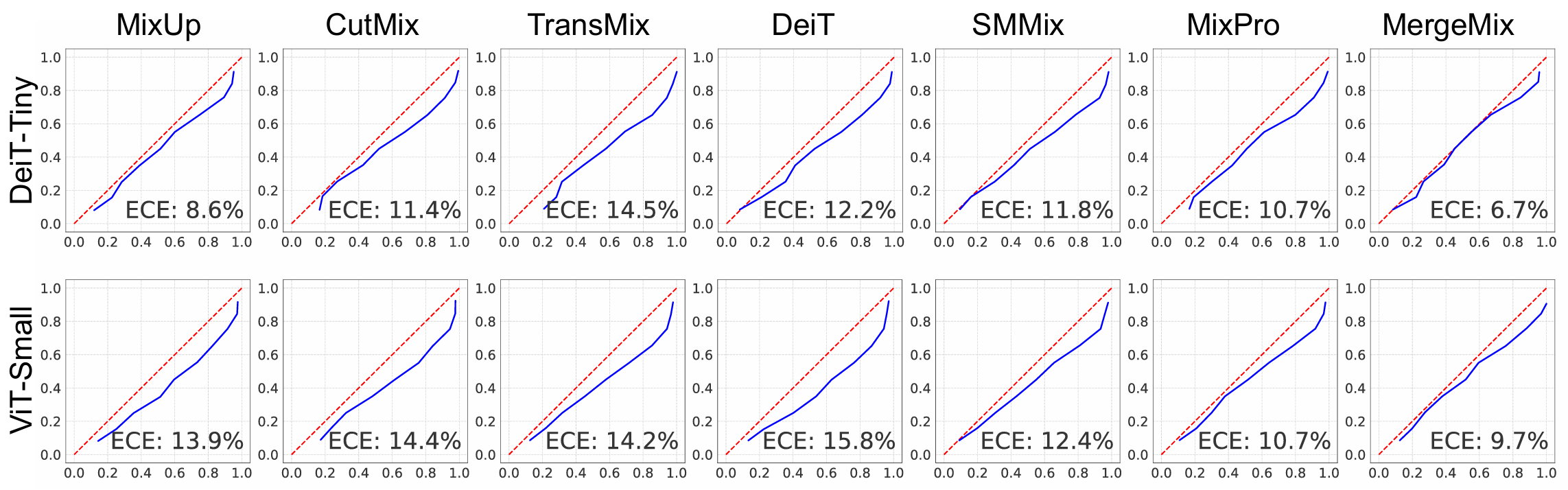
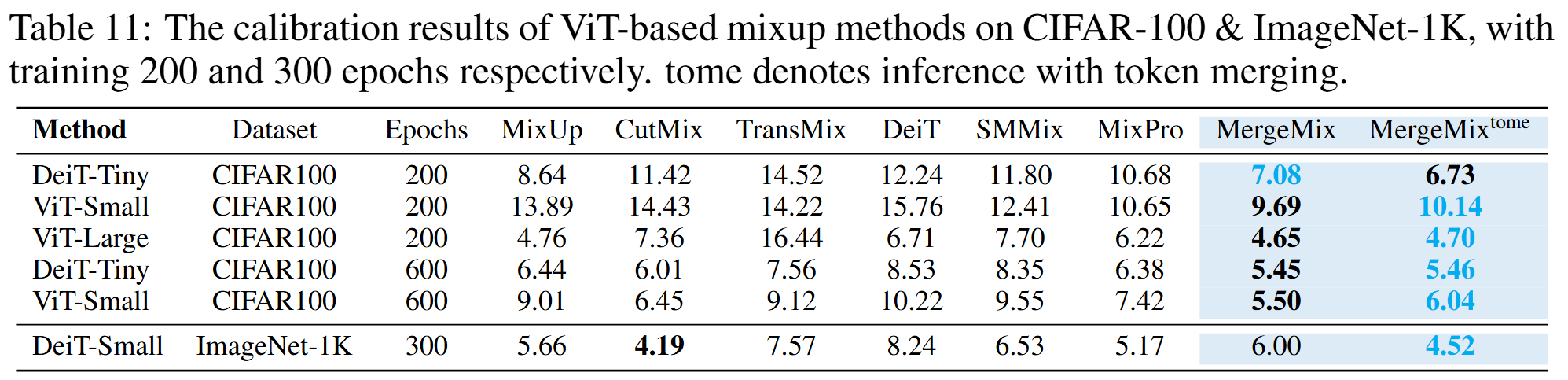
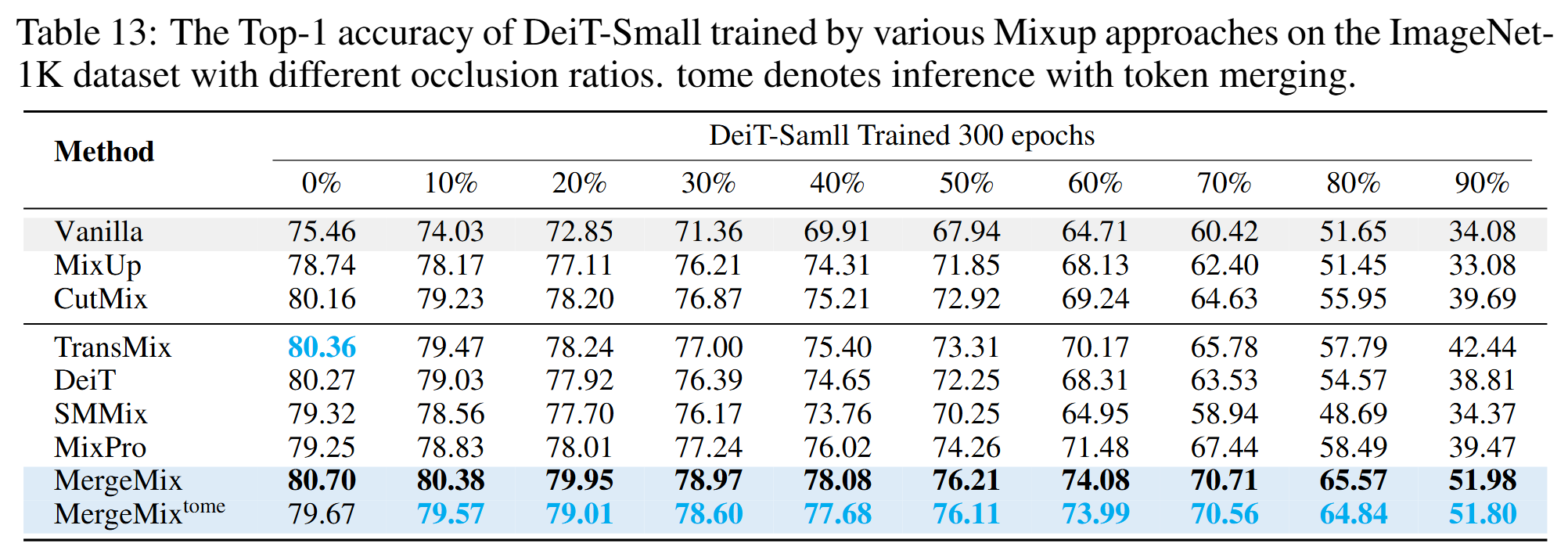
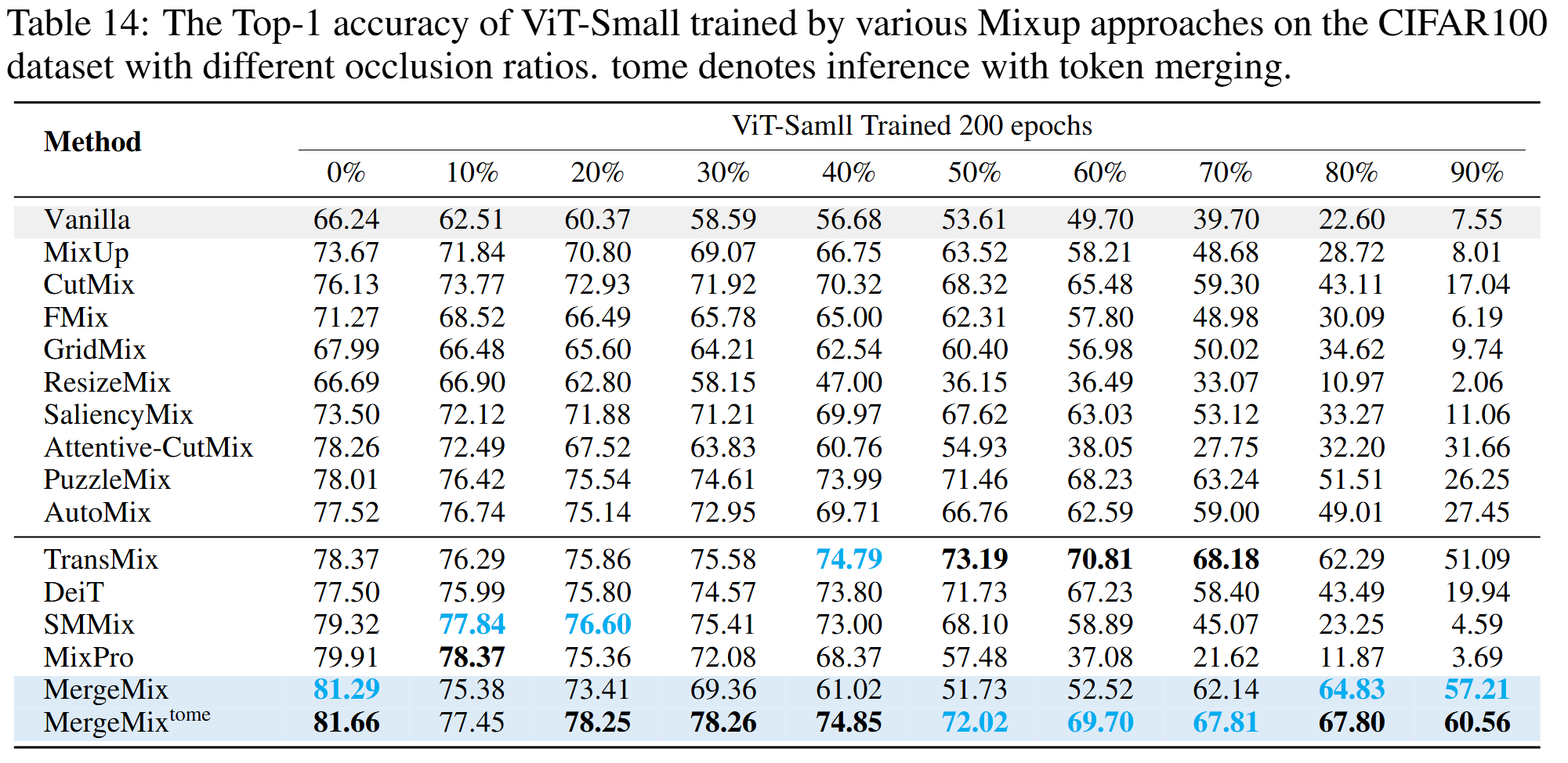
Results of Occlusion Classification
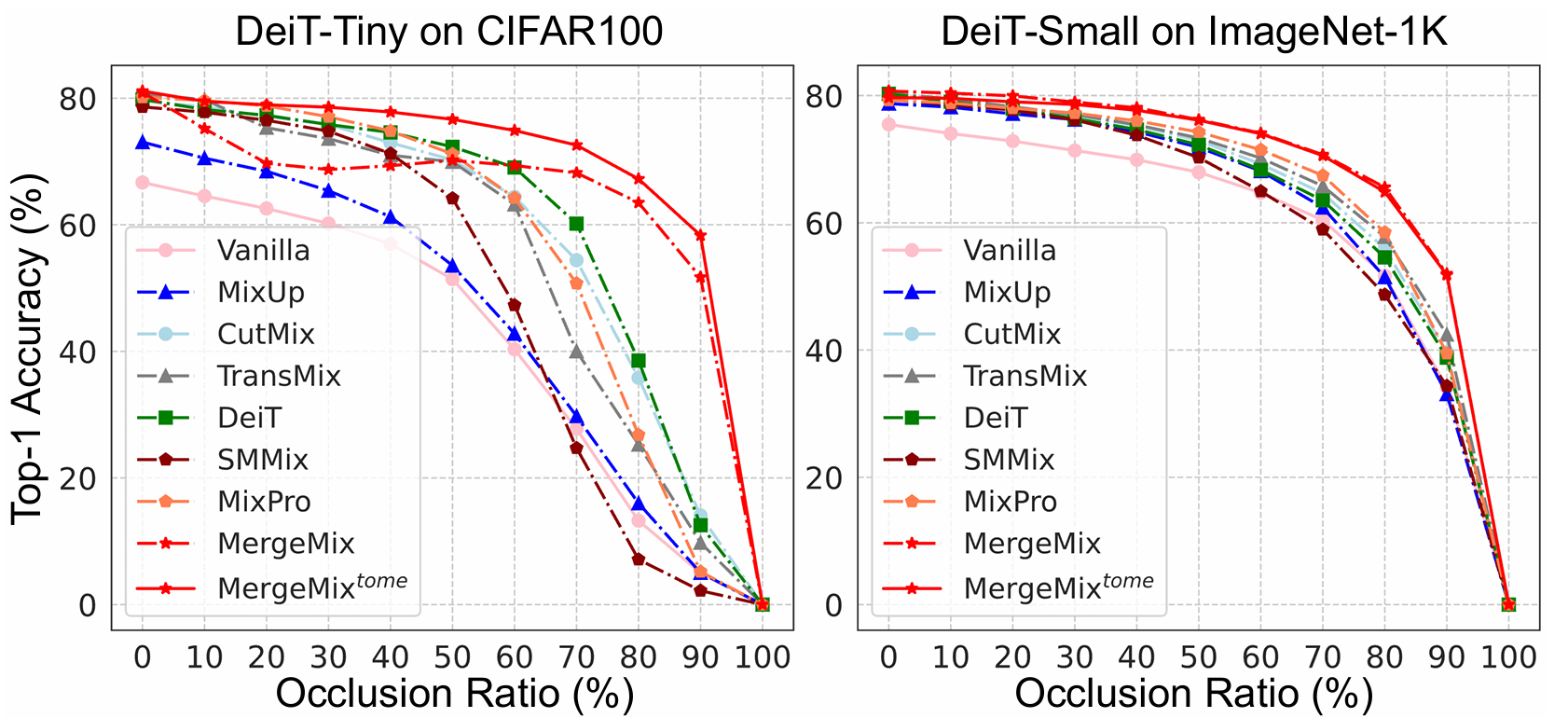
Curves of occlusion classification results on CIFAR100 dataset
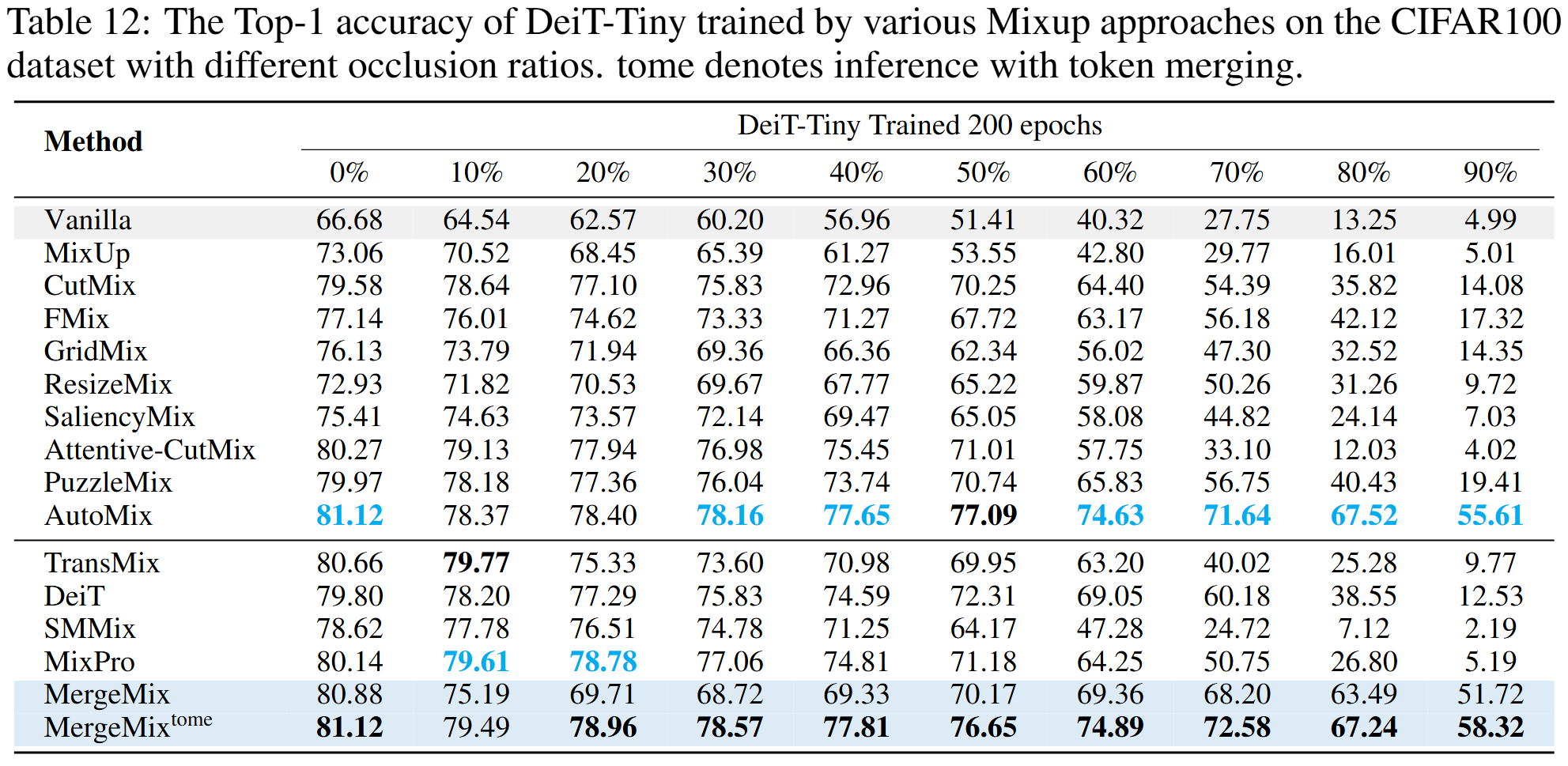
Occlusion Classification Results on CIFAR100 dataset with DeiT-Tiny
Occlusion Classification Results on CIFAR100 dataset with ViT-Tiny
Occlusion Classification Results on ImageNet-1K dataset with DeiT-Small