Preference Tuning with MergeMix
Step 1: Building Preference Pairs
We build preference pairs for MLLM training through data augmentation methods (now support with MixUp, CutMix, ResizeMix, and MergeMix), as we described in the Image Mixing section.
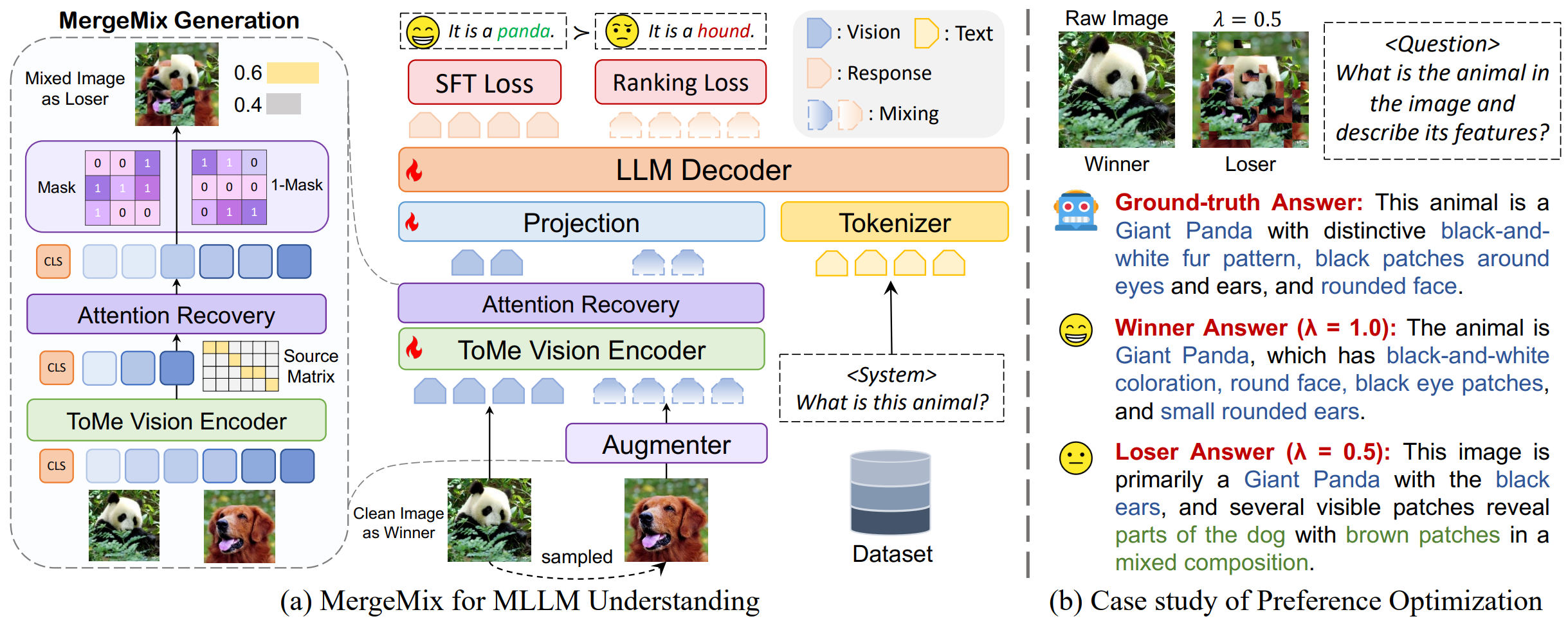
Step 2: Aggregating Mixing Ratio within Preference Loss
We regard the mixed samples as loser and the clean samples as winner, and optimize via SimPO loss without relying on reward models. To align model responses with ground-truth (GT) data, we replace the ranking component of the DPO loss with SimPO. This objective maximizes the likelihood of target responses while incorporating a dynamic margin.
The relationship between the mixing ratio $\hat{\lambda}$ and the SimPO margin $\gamma$ is defined as:
Where $\hat{\lambda}$ reflects information similarity between augmented and raw images:
- • High $\hat{\lambda}$ (High Similarity): Harder discrimination task; $\gamma$ decreases to avoid over-optimization on trivial differences.
- • Low $\hat{\lambda}$ (Low Similarity): Easier task; $\gamma$ increases to strengthen preference constraints for clearer distinction.
By linking the "loser degree" (derived from $\hat{\lambda}$) to the reward margin, the model adaptively scales the optimization strength based on the complexity of the augmented data.
Step 3: Loss Function for MLLM Training
The model is optimized using a composite loss function $\mathcal{L}_{\text{Total}}$, which combines the SFT loss function $\mathcal{L}_{\text{SFT}}$ and the Mixed SimPO loss function $\mathcal{L}^{\text{Mix}}_{\text{SimPO}}$.
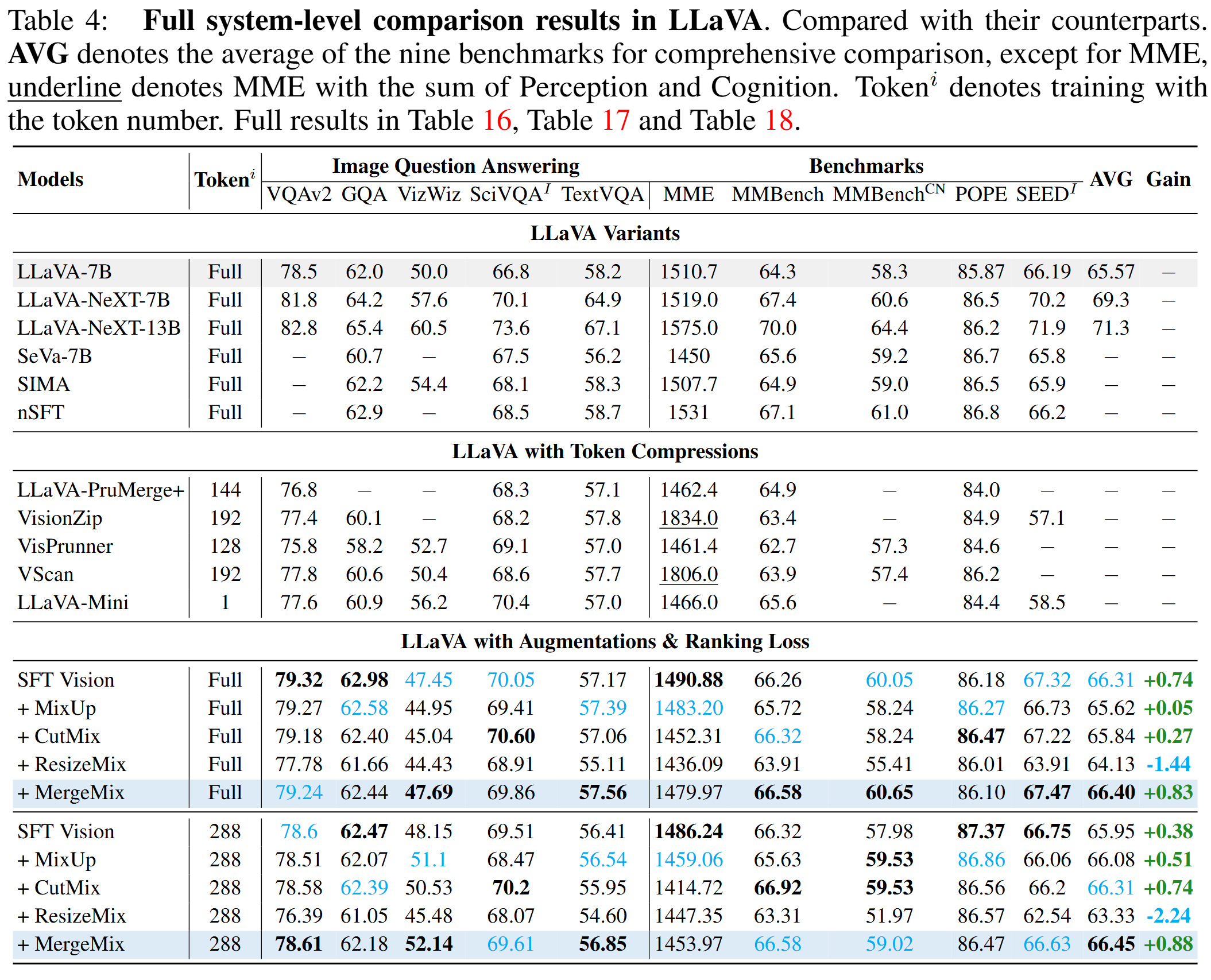
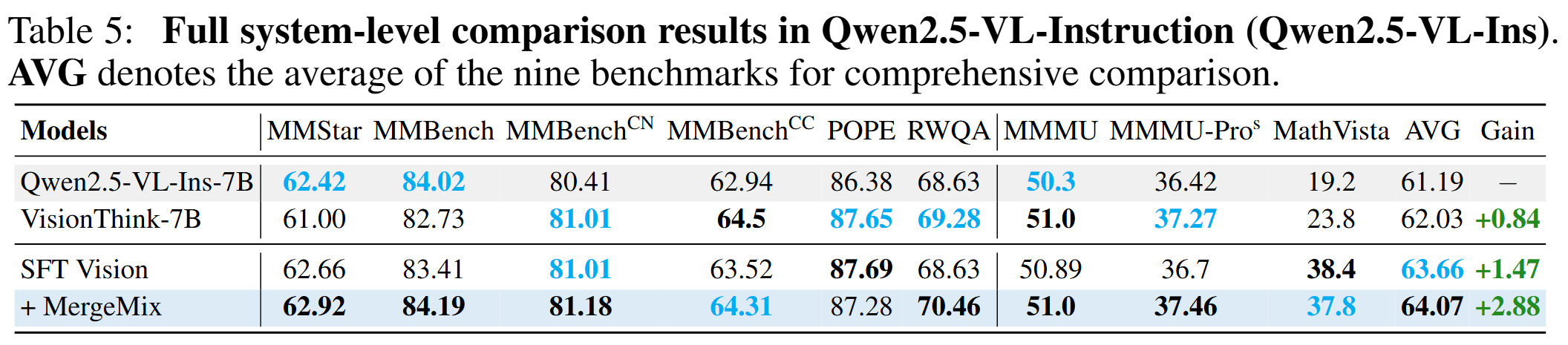
Results of MLLM Benchmark
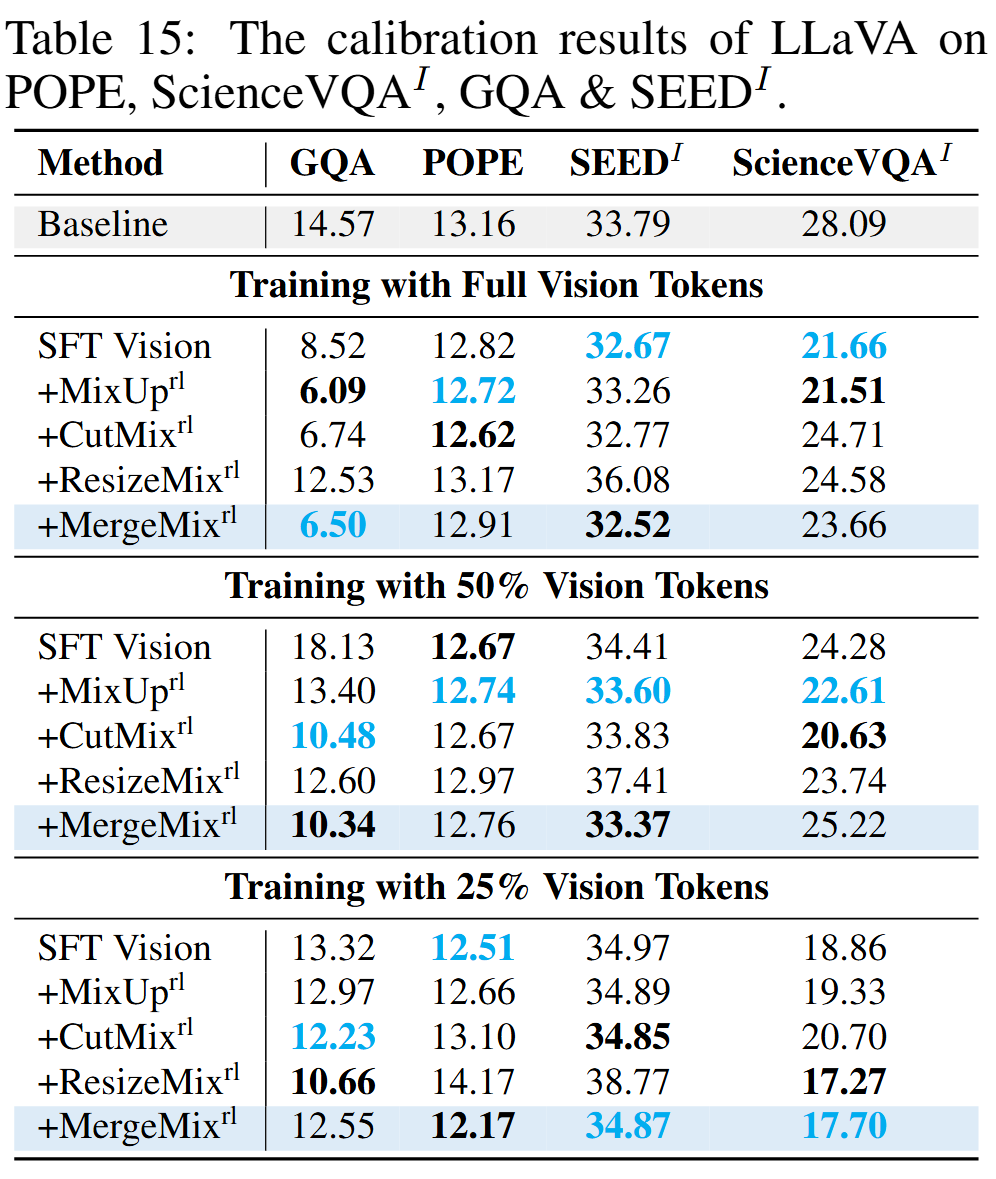
Results of Calibration on MLLMs
More Results of MLLM Benchmark
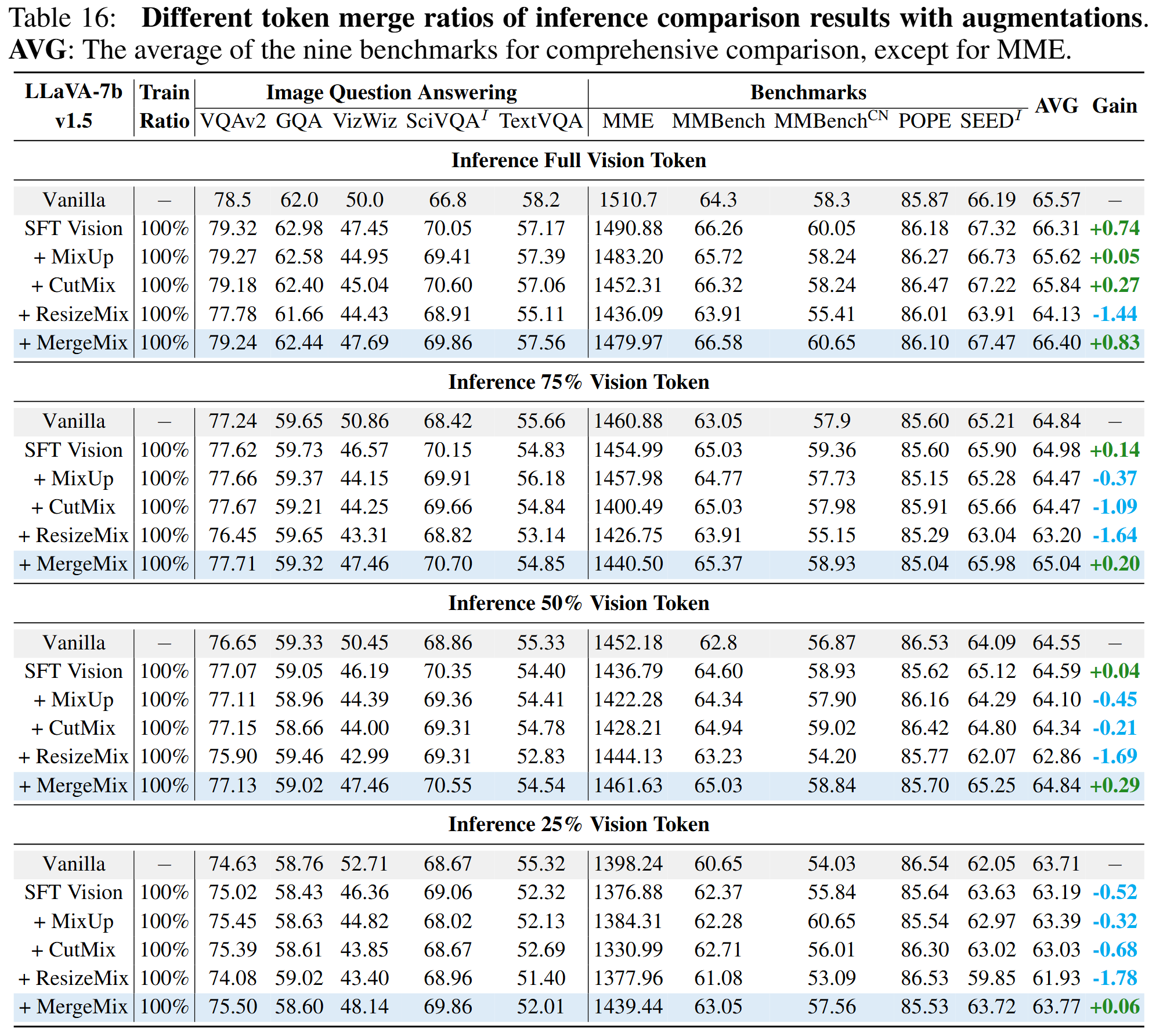
Different token merge ratios of inference comparison results with augmentations. AVG: The average of the nine benchmarks for comprehensive comparison, except for MME.
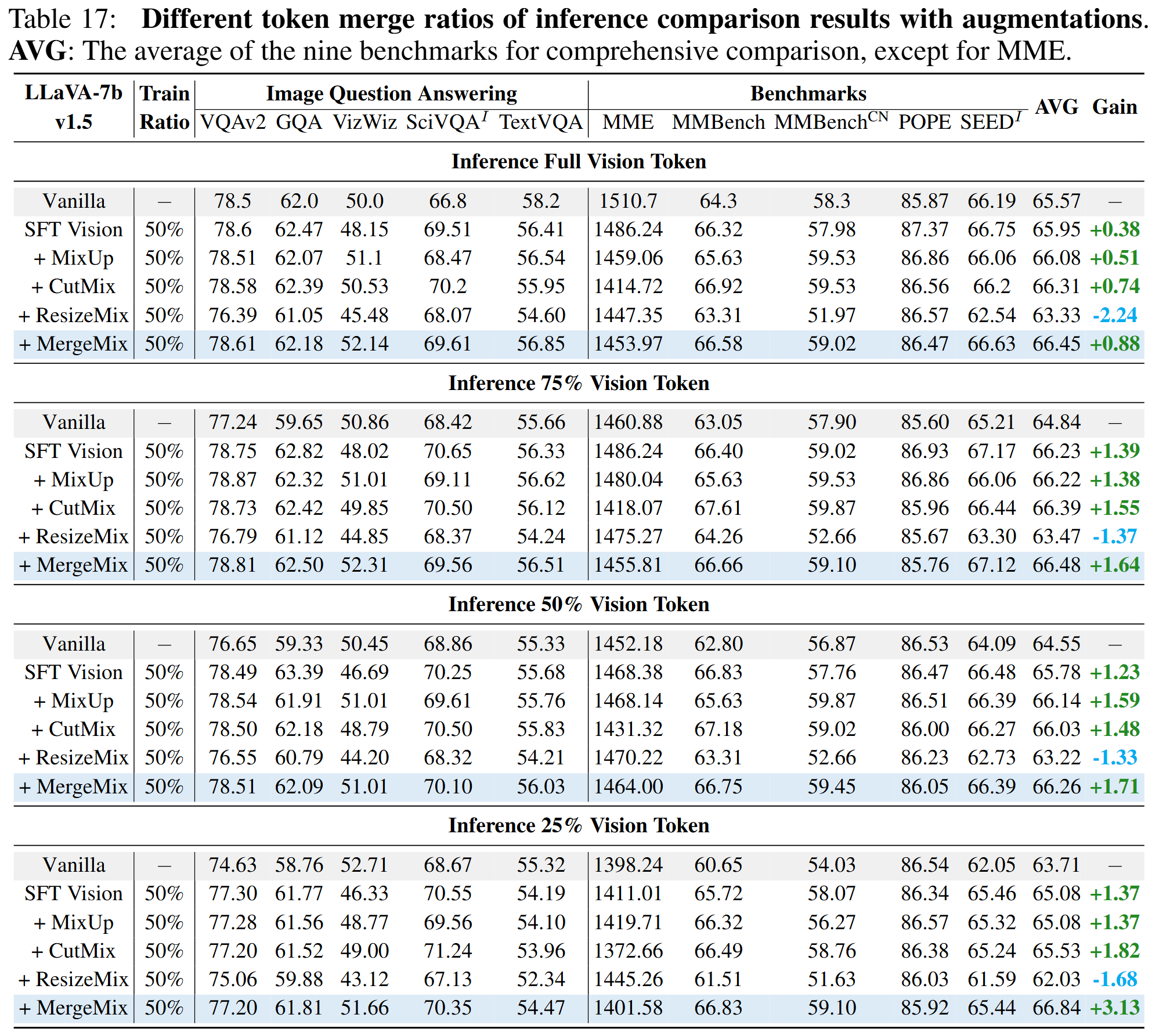
Different token merge ratios of inference comparison results with augmentations. AVG: The average of the nine benchmarks for comprehensive comparison, except for MME.
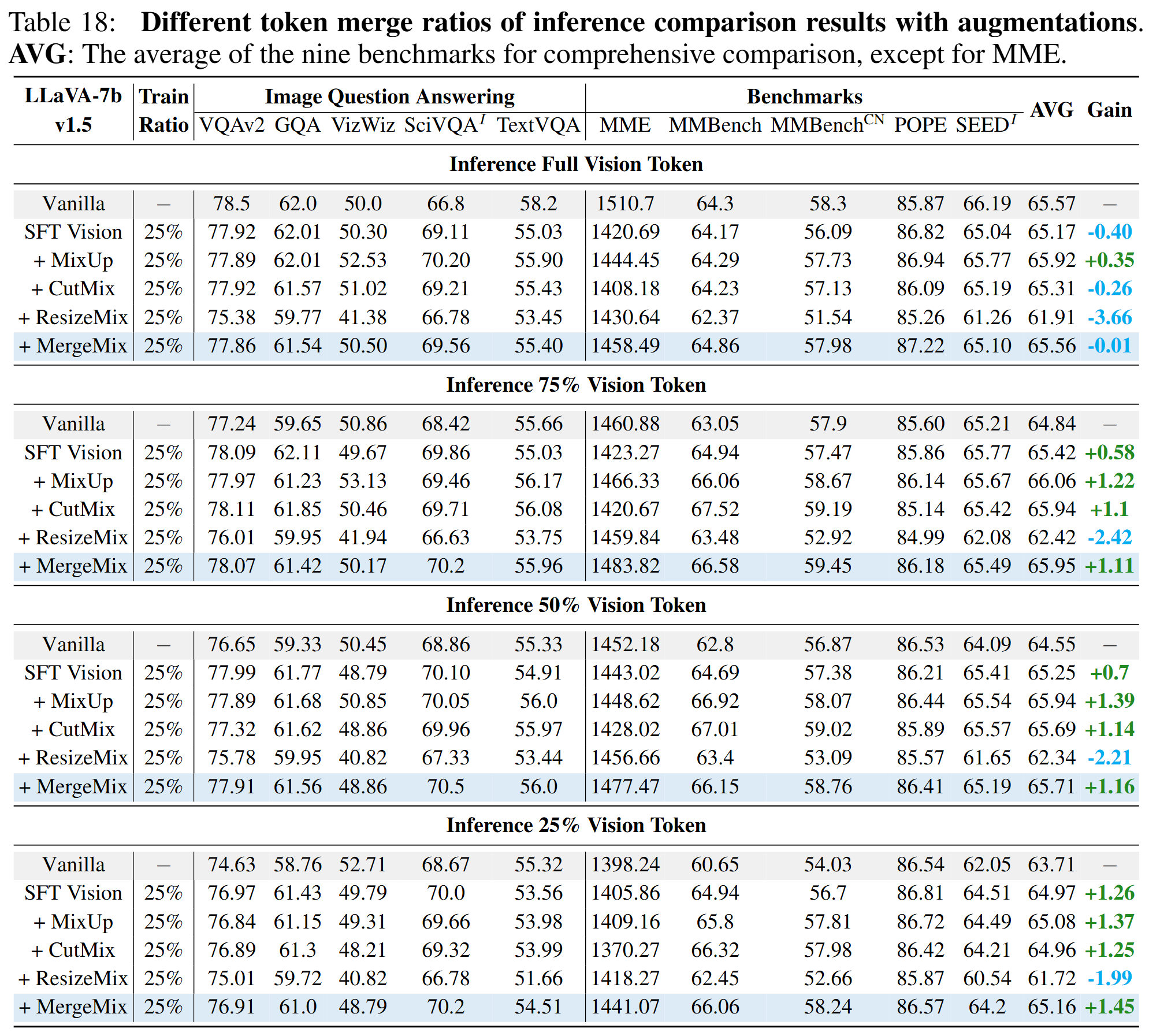
Different token merge ratios of inference comparison results with augmentations. AVG: The average of the nine benchmarks for comprehensive comparison, except for MME.